# CS105x Introduction to Apache Spark 1편
MOOC 사이트인 edx의 Spark 수업을 들으면서 정리하는 내용입니다. 부족한 내용 계속 업데이트해 나갈 예정입니다 😃 혹시 부족한 내용 혹은 틀린 부분이 있다면 언제든 알려주세요!
강의는 CS105x Introduction to Apache Spark (opens new window) 이며 언어는 Python 2.7 입니다.
# Apache Spark (opens new window)란?
- Scalable, efficient analysis of Big Data
- 빅 데이터를 위한 확장 가능한 효과적인 분석 툴
Scalable, efficient analysis of Big Data
# 빅 데이터란?
- 온라인에서의 정보 ( ex. 클릭지표, 네트워크 메세지, 광고 지표 등 )
- 유저에 의해 생성된 정보 ( ex. 페이스북, 인스타그램, 트위터 등 )
- 건강 및 과학 컴퓨팅
- 그래프 데이터 ( ex. Social networks, Road networks.. )
- 로그 파일 ( ex. 아파치 웹 서버 로그.. )
- Machine Syslog File
# 주요 데이터 컨셉
- data model : 데이터를 이루는 컨셉들의 모음
- schema : data model 의 특정 모음을 나타내는 것
# The Structure Spectrum
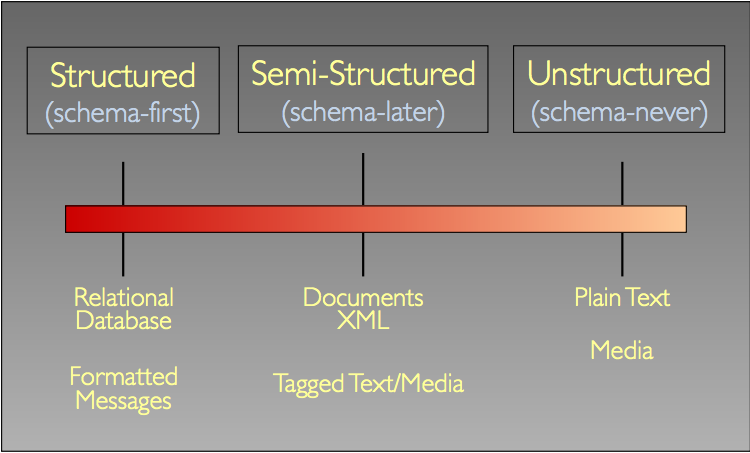 ETL : Extract-Transform-Load
ETL : Extract-Transform-Load
- Unstructured 데이터를 Structured 혹은 Semi-Structured 데이터로 변환.
# 옛날 분석 툴의 문제점
- 모든 걸 다 한 머신에서! > 데이터가 점점 커진다 > 나눠서 처리하자
스파크 프레임 워크
- Provides programming abstraction and parallel runtime to hide complexities of fault-tolerance and slow machines
# 스파크 컴포넌트 구성
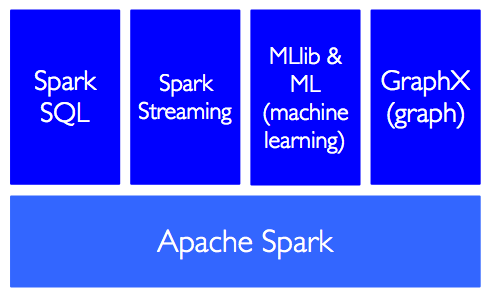 이 강의에서는 SparkSQL을 사용하며 Python Spark (pySpark (opens new window))를 사용함.
이 강의에서는 SparkSQL을 사용하며 Python Spark (pySpark (opens new window))를 사용함.
- pySpark provides an easy-to-use programming abstraction and parallel runtime:
# Spark Driver 와 Workers
- (간단히) Driver Program이 시키면 Worker들이 일한다.
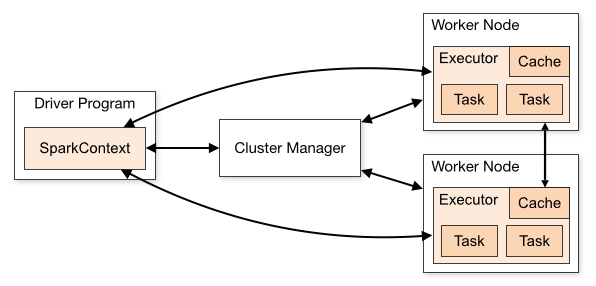
# SparkContext
- 스파크가 어떻게 어디서 클러스터를 접근할 지 알려준다.
- pySpark 나, Databricks CE에서는 자동으로 SparkContext를 생성
- iPython이나 프로그램에서는 반드시 new SparkContext를 해주어야 한다.
그리고 sqlContext 객체를 생성. sqlContext를 이용하여 DataFrames를 생성.
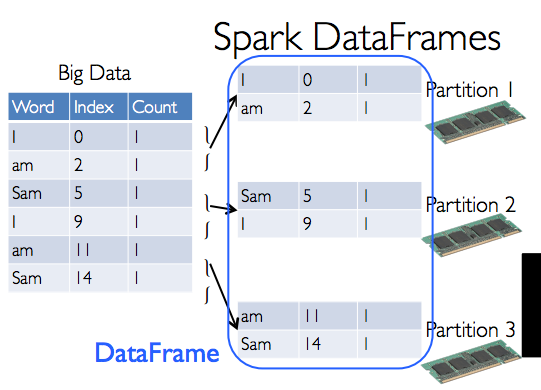
# DataFrames
- 불변 객체 (Immutable once constructed). 한번 생성되면 절때 불변!
- parellel 하게 작동할수 있음.
- Python collection(list) 를 사용할 수 있음
- Spark나 pandas DFs를 DataFrame으로 바꿀 수 있음
- HDFS에서 가져 올 수 있음.
- 각 로우는 Row 오브젝트임
ex )
>>> row = Row(name=“Cheese”, age=11)
>>> row
Row(age = 11, name=“Cheese”)
>>> row[‘name’], row[‘age’]
(‘Cheese’, 11)
>>> row.name, row.age
(‘Cheese’,11)
- 두개의 타입의 작업이 가능 : transformation 과 action (기억하자!)
# Transformation
- lazy (not computed immediately
- transformed DF는 action이 run 되는 시점에 실행이 됨
- Persist (cache) DF는 메모리 혹은 disk에 저장됨.

# Action

# 스파크 프로그램의 life cycle 정리
- 외부 데이터를 가져오거나 “createDataFrame” 을 통해 DF을 생성
- -> transform 을 이용해 새로운 DataFrame에 lazy로
- -> cache()를 이용하면 다시 사용 가능
- -> action을 통해 parallel하게 실행되고 결과 값을 생성