# [후기] Tech planet 2016
SK planet에서 주최하는 Tech planet 2016 (opens new window)을 다녀왔다.

Commerce Everywhere
라는 주제로 다양한 프로그램 (opens new window)이 발표되었다.
최근 핫한 기술들을 화두로 40분씩 발표가 꽉꽉 차있었다.
빅데이터와 머신러닝, 딥러닝 그리고 그를 이용한 추천에 대한 이야기가 행사를 가득 매꾸고 있었고,
SKP에서 뿐만 아니라 전 세계적으로도 트랜드인 챗봇에 대한 시간도 있었다.
주제만큼이나 다양한 글로벌 회사들의 후원도 있었는데, 오전 키노트에서는 알리바바와 IBM의 핵심 연구원들이 행사의 문을 열었으며 전 세계적으로 딥러닝과 챗봇 플랫폼의 선두로 나서고 있는 구글과 페이스북에서도 재밌는 경연의 시간을 가졌다.
아침 9시부터 저녁 6시까지 쉴 틈 없이 꽉 차있는 프로그램을 듣고 나니 녹초가 되었지만, 평소 키워드만 듣고 흘려보내던 최신 트렌드의 기술을 짧은 시간안에 전파 받은 것 같아 뜻깊은 시간을 보낸 것 같다.
특히, SKP 매니저분들의 발표는 대부분 사내, 특히 11번가 (opens new window)에 적용된 실용적인 내용으로 내가 일하고 있는 분야에 대해서도 많은 영감을 주었다.
 이외에도 다양한 [전시 부스들](http://techplanet.skplanet.com/exhibit.html).
이외에도 다양한 [전시 부스들](http://techplanet.skplanet.com/exhibit.html).
아주 작은 아쉬운 점이 있다면은..
- 3트랙이 동시진행되면서 직접 못들은 것들도 있고 (컨퍼런스 갈때마다 느끼지만ㅠ 난 헤르미온느가 아니다..)
- 행사장 규모에 비해 너무 사람이 많아 자리가 좀 비좁았다 (유료행사다 보니 노쇼가 적었던것 같다. 좋은건가?)
- 다양한 스타트업 부스들이 있었는데 세션 중간 쉬는시간이 적어 제대로 돌아보지 못했다ㅠㅠ
- 그리고 언어 이야기가 한 세션 뿐이였다. (이번 주제는 요게 아닌것 같아 그냥 이건 소소한 내 의견)
위의 아쉬운점은 어느 기술 컨퍼런스를 가나 있는거니 그냥 툴툴거리는 정도로 생각하면 될 것 같다.
그리고 이번 기념품은 VR Box와 텀블러! VR박스는 페이스북 페이지 (opens new window) 에서 해시태그 #techplanet2016 #테크플래닛2016 이벤트를 통해 받았다.

강의 자료 : SK플래닛 기술 블로그 (opens new window)
마지막으로 오늘 들은 내용들을 잊지 않기위해 러프한 노트이지만 공유하고자 한다.
# 내 스케쥴과 주제
| topic | 내용 |
|---|---|
| [1] Large-scale Robust Online Matching with Its applications in Alibaba | 알리바바의 응용 프로그램을 이용한 대규모 Robust 온라인 매칭 |
| [2] Cognitive Computing with Multilingual Watson | 다국어 왓슨시스템을 통한 인지컴퓨팅 |
| [3] 파이썬 에코시스템 | 파이썬 커뮤니티와 파이썬 생태계에 대해서 설명하고 다양한 파이썬 활용 사례에 대해서 소개 |
| [4] Visual search at SK Planet | SK Planet에서 개발한 Visual search technology와 11번가 패션상품 검색 적용 사례 소개 |
| [5] Apache Spark은 어떻게 가장 활발한 빅데이터 프로젝트가 되었나 | Spark 핵심 개념과 인기의 비결, Spark 도입 전략 소개 |
| [6] In-App Messaging and Chatbot | In-App Messaging SDK 개발과 적용 사례소개, 2016년 화두인 대화형 커머스(Conversational Commerce)와 Chatbot |
| [7] Google Tensor Flow & Machine Learning in the Cloud | 구글의 딥 러닝 클라우드 제품들과 텐서플로우 소개 |
| [8] 빅데이터와 자연어처리 기술을 이용한 11번가 상품 추천 | SK플래닛에서의 자연어처리와 텍스트 마이닝 기술 소개와 이를통한 상품 추천, 마케팅 및 컨시어지 서비스 기술 개발 등에 활용하는 현황을 소개 |
| [9] Facebook Chatbot M messenger | 인공지능과 봇의 역사를 간략하게 짚어보고 봇을 만들며 활용 할 수 있는 베스트프랙티스(best-practice)들을 논의 |
# [1] Large-scale Robust Online Matching with Its applications in Alibaba

- Robust matching
- Online matching
# collaborative intelligence
- machine intelligence : Q&A engine
# [2] Cognitive Computing with Multilingual Watson
- 자연어 처리를 위한 머신러닝

# congnitive computing
- machine leanging
# diff w/ programmiatic computing
learn behavior rather than predefined specification or behavior
정보의 변화를 받아드림.
watson 퀴즈 프로그램에서 이겼음.
언어에 대한 deep analysis 등
watson이 헬스케어에도 쓰임
rich-data, keep tracking informations
# api
- personality insignt
- language identification
- machine translation
- speech to text
- conversation 등등
 - intent 를 나눠서 질문에 따라서 intent를 나눈고 그에 따라 answer
- intent 를 나눠서 질문에 따라서 intent를 나눈고 그에 따라 answer
# 알고리즘 컨셉
형태소 분석한걸 머신 러닝한다. 각 나라의 회사에서 제공받음.
한국은 SK가 주고 잇네
영어로 머신 러닝을 하지만 같은 방식으로 다양한 언어들도 러닝을 한다.
다양한 언어들도 다 같은 퍼포먼스를 낸다
만약 질문을 알아듣지 못하면 관련한 질문 리스트를 다시 돌려줘서 답을 찾을 수 있게 해준다.
# Watson Conversation
# data extraction
article에서 분석을 위해 각 알맞는 도메인들을 꺼냄
data, person, age 도메인 등등..
기존에 배웟던 도메인을 다른 글에서 도메인을 꺼내는데 사용함.
글 속에 잇는 사람이 위키피디아에서 context를 이해해서 누구인지 찾아냄
참고 : watson develop cloud (opens new window)
# [3] 파이썬 에코시스템
# 파이썬이란
89년 크리스마스에 만들엇음.
멀티 페러다임 - 객체지향 + 스트럭쳐 프로그래밍
functional — 지원하는가.? 제한적이지만 가능하다. // 파이썬 3.6 에서 개발중. doc 참고
다양한 구현체들이 있음.
- c로 구현된 python
- python python >> pypy
- java jpython
- 등등
indent 강제하는 언어
pep20 : 파이썬 스펙? 기능제한? 파이썬이 지향하는 철학
complex is better than complicated - many vs difficult
쉽고 명확하고 단순한 것
# 파이썬 어디에 좋은가
- os interface
- 인터넷 프로토콜
- 소프트웨어 엔지니어링 등등등등
- python package index : 파이썬 리파지토리들
pip install {package_name}
docker도 처음에는 파이썬으로 짜여짐.
- 프로토타입이 파이콘에서 처음 발표됨 ( dcloud ?)
- 도커 회사에서 > pip를 py-docker file이 올라오니 이름 저작권 내려라.
# use cases
- drop box 등등
- 막 말하자면 다 쓰고 잇다.
# 웹 프레임 워크
- flaskm, django pyramid tornado
# 회사
- 인스타그램 레딧 프레쯔
# 빅 데이터 - PyData
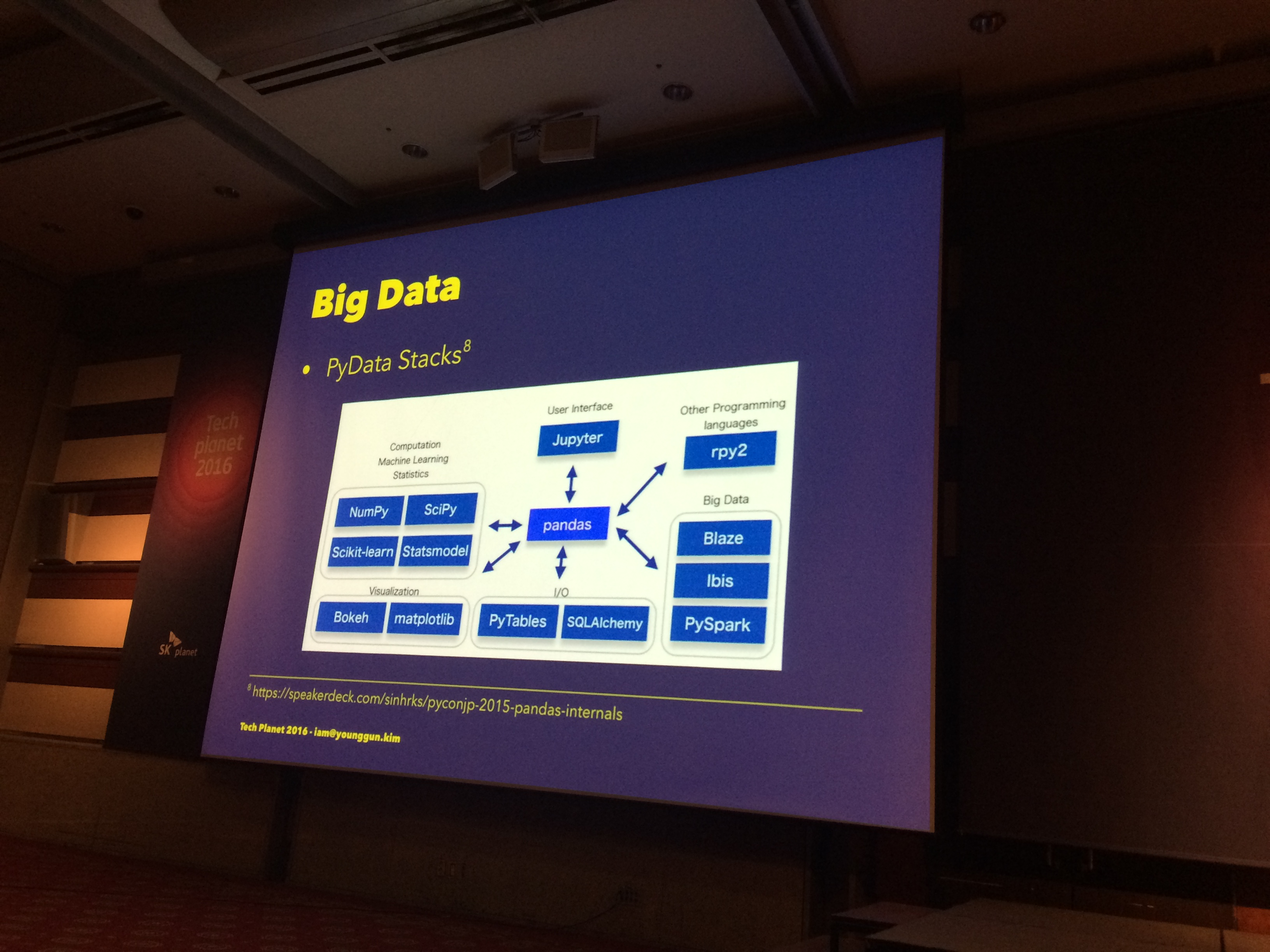
# 과학
- NASA (중력파를 파이썬으로 검증?!)
# 교육
- bbc : microbit
# CG
- maya, : 애니메이션 관전들을 이어서 부드럽게 연결하는걸 파이썬 스크립트로 처리한다고 함.
- Blender
- Disney : https://github.com/disney (opens new window)
# 음악 분야
- Ableton Live
# 제조업
- philips, d-link
# 게임
- 문명!
- 몬스터 슈퍼리그 - 스마트 스터디
- python booster : c++로
# 스마트스터디 use case
- 빠르게 후딱 만들다 보니 마이크로서비스 가 만들어짐
- api service들에서 사용됨, 700여개의 앱을 관리
ex) 게임 몬스터 슈퍼 리그
- 게임에서는 orm을 쓰기 어려워서 걷어내고 제작
- 어드민 툴
- ranking : flask
- 동접이 높아도 잘 되고 잇음.
# 파이썬이 이리도 유명한 이유
커뮤니티.

좀 더 friendly 하당 ㅎ
파이썬 코리아, 파이콘, 등등
파이콘
# 처음 시작이라면
- jupyther / 주피터 노트북
- pip and awesome list
- 위와같은걸로 하면 더 편행
# python 3 로 시작하세요
- 2는 더이상 release 안될 예정 (PEP404)
- 패키지가 2만 지원한다. >> 3로 찾아봐라 80%는 잇을꺼임
- 20% ? 만든 사람에게 push push 너만 2다.
# [4] Visual search at SK Planet
- 주로 패션 검색 ( 11st)
# 개발 배경
- 쉽게 검색
- ex) 키워드
# 개발 목표
- 영상을 쿼리로 상품 검색
# 사전 지식
# 딥러닝
- 딥 뉴럴 네트워크 + 머신 러닝
- artificial neural network - 사람의 신경망을 모방한 컴퓨터
- 학습 할 수 있음
- 학습을 위한 데이터가 필요 (딥러닝의 단점)
- 학습시간이 오래걸림
- 종류 : dbn rnn cnn …
- 참고 : 최찬규 매니저의 테크플래닛 2015 발표 (opens new window)
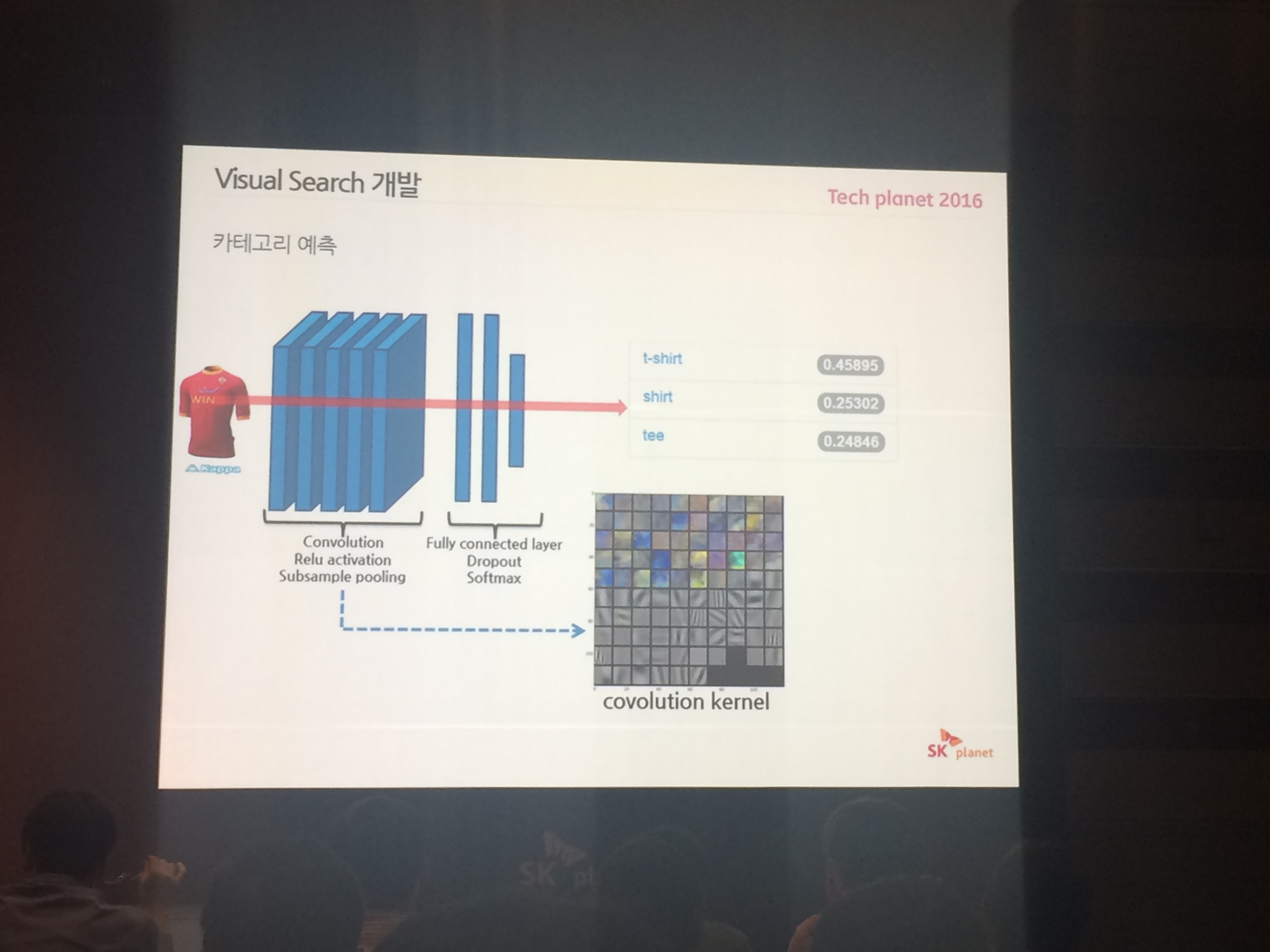
# 첫 접근 방법
- 영상 입력
- 카테고리 예측(딥러닝) - ex) 티셔츠, 가방, 신발 등
- 관심영역 추출 - grab-cut saliency , Hog + SVM를 통한 검증
- 특징 추출(딥러닝) - pattern feature , Color feature
# 카테고리
- 처음 카테고리가 잘 나오지 않으면 뒤에가 다 잘 안됨.
- 최대한 다양한 카테고리가 나오게 해서 확률을 뽑아서 동의어 처리를 통해 카테고리를 뽑아냄
# 관심영역
- 영역을 crop 해서 관심영역 추출 — 문제점 : 상하의가 같이 잇으면 한개씩 접근해야해는데 하나의 옷처럼 인식
# 개선
# 기존 시스템에 대한 평가
ask to 기획자. 잘 됏나? 잘 됐다..
but.. single object에 대해서만 잘된다 : 판매자는 한장의 사진에 여러 상품을 넣기도 함
단순한 배경에서 : 소호몰 같은 경우 복잡
실제 DB 안에는..
멀티 오브젝트
야외 촬영 ( 공항에서 트렌치코트, 가방을 들고 잇고 부츠를 신고 있음)
유사상품이다 아니다를 딱 잘라 말하기 어렵다. ex ) 남/녀 차이
# 개선 방향
- 여러 상품이 잇어도 모두 검색 : 딥러닝 detection 기술 적용
- 야외도 해주자 : 딥러닝을 적용한 특징 추출
- 누구나 유사하다고 느끼도록 : 속성 기반의 인식 (단추, 벨트 등)
# Detection

# Feature extractor
- Deep feature

유사상품에 대한 ground truth를 만드는 것이 어려움 (유사한거다 아니다 판단)
공개 DB를 대상으로 가능성 평가 —> ukbench dataset (opens new window) 대상으로 검색 실험
symentic 검색에 매우 적합하다 라는 결론을 내림
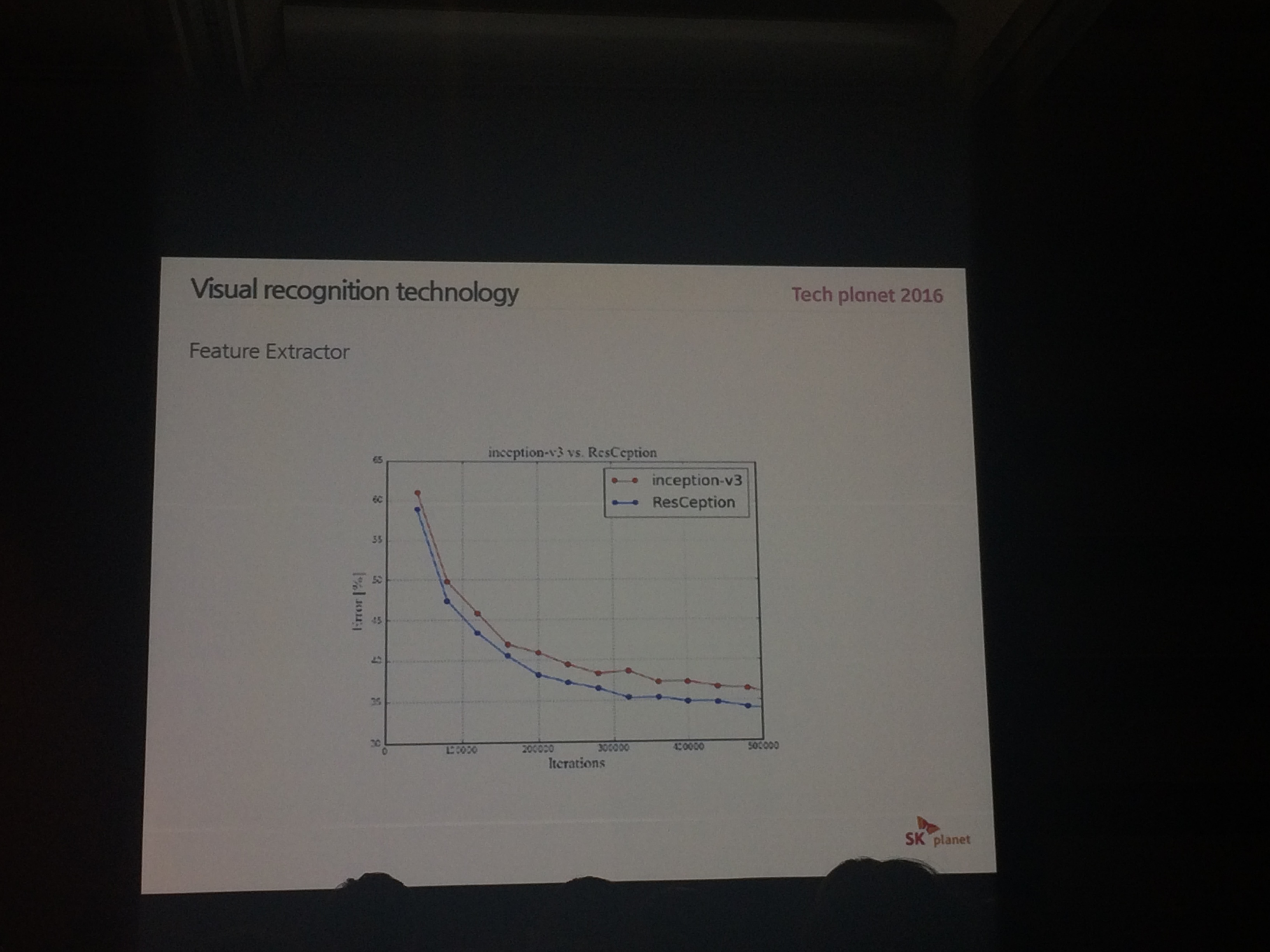
Google lab?
MS : residual learning : 너무 많은 메모리, 학습시간 이 듬
두개를 합해서 특별한 feature extractor를 만듬 : ResCeption
# Attribute
- 의상의 속성
- 어떤 것이 비슷한 것인가 : 동일한 속성
# 먼저 데이터 셋을 모으자 ( Fashion-attribute dataset)
- 100 맨먼스
- 일년동안
- 90여개의 속성
- 조합하면 수천가지
- detectio을 위해 ROI 데이터셋. 의류의 위치를 알아낼 수 있는
- multi-label classification - > conditional probability 큰 클래시피케이션이 잇으면 뒤에있는 값에 영향을 줌 ex) 바지 뒤에는 티셔츠가 들어올 수 없고, 청바지, 레깅스 뭐 이런것만 올 수 있음.
하나씩 통과하면 대표되는 값들이 넘어가며 feature를 추출

- Feed-forward network
# Guided search
- 영상이 주워졌을때 배경/상의/하의/신발 등이 섞여있음 >> 검색되기 원하는 상품을 선택하도록 하자.
- 판매의 경우 입력된 tag 정보를 이용. >> (문제) 판매자의 tag 정보가 정제되어잇지 않다.
넘어온 태그를 자연어 처리(형태소 분석, 동의어 처리 등)를 통해서 키워드를 추출
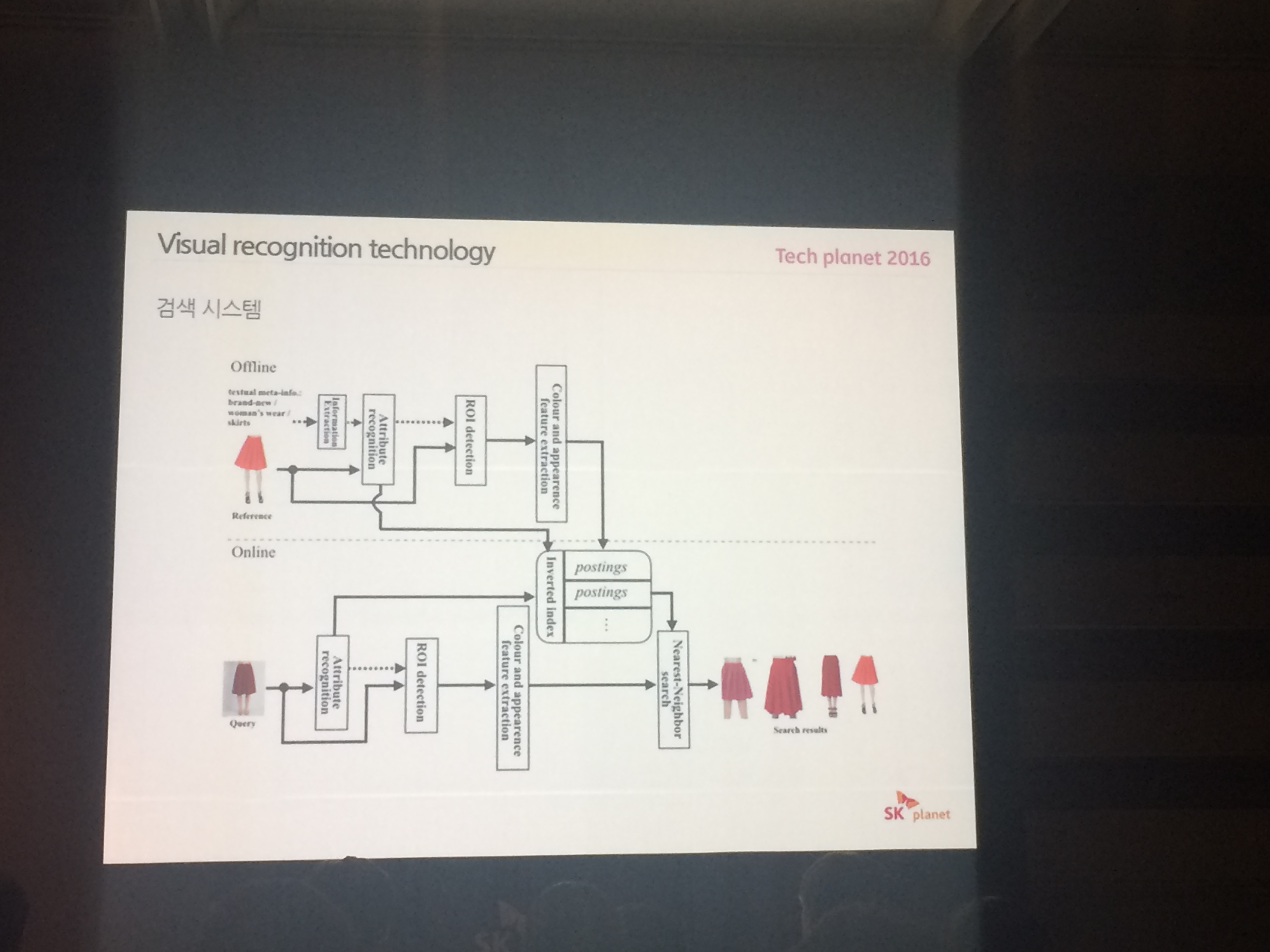
# 검색 시스템
information을 뽑고 , 속성을 뽑아내고, 그 속성을 index로
# 분산 검색 시스템 적용
# 문제
- 검색 대상이 너무 많다 ( dataset이 너무 크다)
- DB관리도 해야한다
- 결론 : redis 기반의 분산 인메모리 병렬처리 기술 적용
- 효율적인 DB관리
- 검색 속도 개선
- Mosaic : 캐시 시스템 적용.
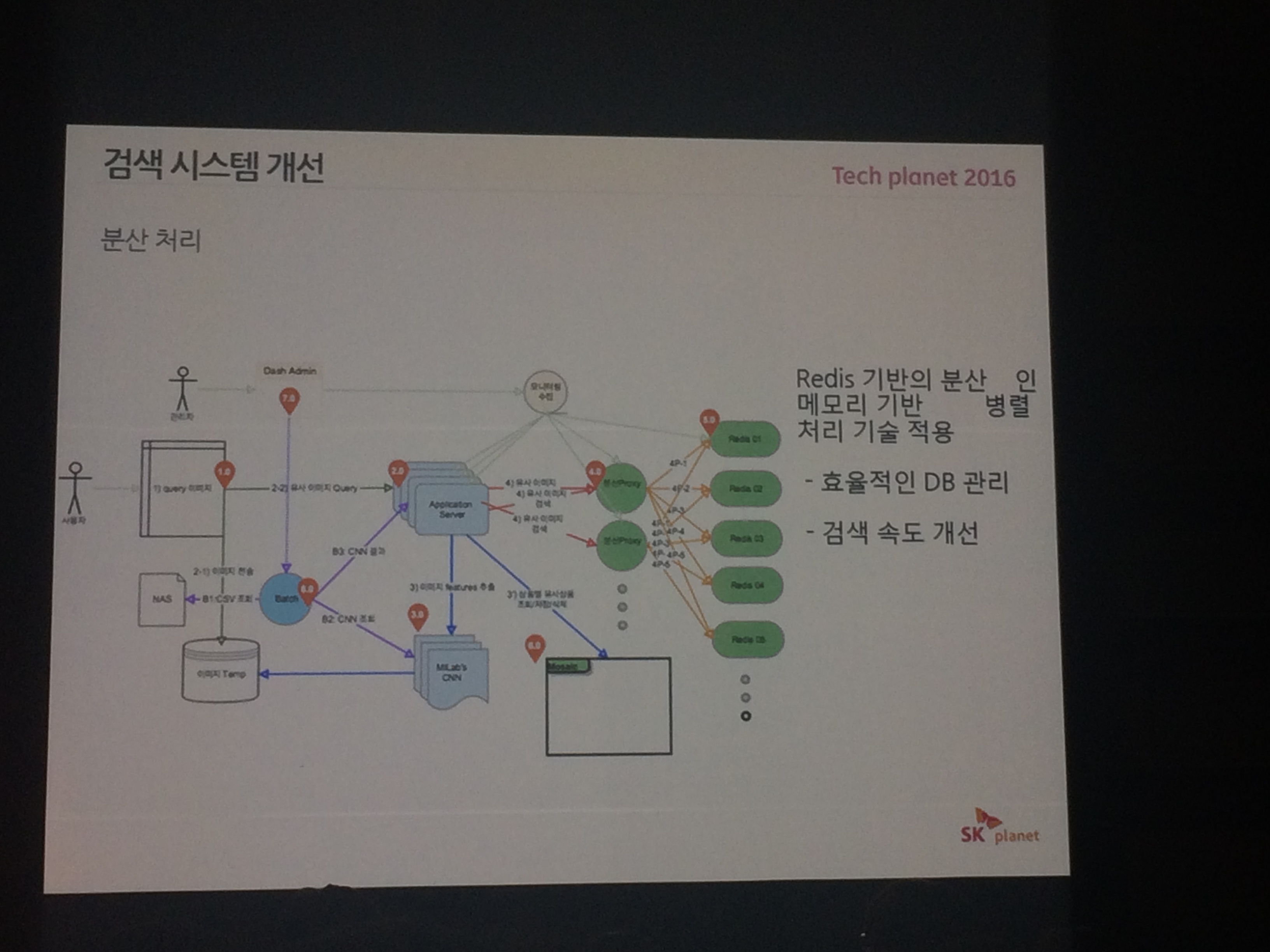
참고 : Visual Fashion-Product Search at SK Planet 논문 (opens new window)
- 11 번가 앱에 beta로 올라가 잇으니 사용해 볼 수 있다.
# [5] Apache Spark은 어떻게 가장 활발한 빅데이터 프로젝트가 되었나
# Saprk
- 많은 양의 데이터를 (수gb - 수천 tb)
- 여러대의 컴퓨터를 이용해서 (clustering) (1 ~ 수천대)
- 분석
# 왜 인기가 잇을까
- 아파치 탑레벨 프로젝트 — 안정적이고 활발한 커뮤니티가 형성되어야 함
# 아차피 특징
- 인메모리컴퓨터 엔진의 압도적인 성능 (2배에서 100배
- 쉬운 사용법
- sql, 스트리밍 머신러닝 R등의 확장성
# 인메모리
# 기존 데이터 분석
매우 무식한 방식 : 연산 > 데이터 저장 > 연산 > 데이터 저장
반복 연산일수록 효율이 떨어짐
분산 처리 및 장애 복구를 위한 어쩔 수 없는 설계상의 선택.
클러스터 컴퓨팅에서는 일부 컴퓨터가 고장나는 경우에 대비 해야함.
# spark
- 다단계의 연산이나 반복 연산의 경우 중간 결과를 메모리에 저장 (빠르게)
- 데이터가 전부 들어갈 정도의 메모리가 필요하다.
- 실제로 데이터도 분산 저장 연산도 분산처리
# fault tolerance
- 그럼… 중간 복구 지점이 없는데 (장애복구)는 어떻게?
- 누락된 데이터 연산 과정을 기록한 lineage(계보) 리니지 ㅋㅋㅋ 를 이용해 해당 부분을 처음부터 다시 계산.
- 무식하긴 해도.. 메모리를 활용한거기 때문에 다시 하는것도 빠름.
# RDD
Resilient Distributed Dataset
탄력잇는 분산 데이터셋
분산 처리 및 장애복구가 가능하다 라는 뜻을 내포
“Scala", python java 지원
기존 맵 리듀스보다 훨씬 간단
spark shell 제공 , 탐색적인 데이터 분석이 가능
제플린과 같은 시각화 노트북 툴 활용 가능
탐색적인 데이터 분석 >> 인터렉티브 하게 코드 실행이 가능. 질의하고 확인하고 질의하고 확인하고
# 확장성이 좋음
- Spark SQL : 코드대신 sql로 데이터 분석
- Spark streaming : 코드 베이스를 많이 바꾸지 않고도 실시간 분석 가능
- MLLib
- GraphX : 대용량 그래프 분석 등
- sparkR
- 제플린
- 스팍을 익히면 다른 분야로도 건드리기 쉬움
# 이렇게 되기까지
- 열정 넘치고
- 지라에서 창립자도 열심히
- 성능향상 & 인터페이스 개선
- 투자를 잘 받음.
# 예상되는 질답
# spark이 하둡을 대체 할까요?
- 네 - 니요.
- Spark을 단독 설치해도 되고 하둡 작업을 스팍으로 옮길 수 도 잇긴 하지만….
- 스팍이 shuffling이 많이 일어나는 연산들 ( id별로 그룹을 만든다던가) 하는 경우 Spark에서 잘 안되는 경우가 잇음.
- 물론 하둡을 사용해도 굉장히 오래걸리거나 비효율
# 공부해야할까용?
— 네네 시작해보세요. 고성능, 편리한 인터페이스, 시간과 비용도 많이 아낄 수 있고 , 점점더 많이 쓰이고 있으므로 커리어 면에서 지금 시작하십쇼
# 첫 데이터 분석!?
— GA, firebase Analytics facebook anaylitics 등 무료 분석 툴 먼저 사용해 보고 그 다음 spark 를 써보세요
# 기존 하둡을 번속하고 있습니다. spark 으로 옮길까요?
- 네넹 저는 그랫습ㄴ다. cloud로
- 2~5개 정도의 성능향상과 코드가 간단해지고 생산성이 크게 향상
# 쓰고있는 클러스터 메모리가 부족합니다.
- 반복 작업이 아닌 ETL 의 경우 메모리에 꼭 올릴 필요 없으므로 문제가 없당 .
다만 grouping ( shuffling이 많은) 연산의 경우 메모리가 넉넉해야하니 (작업이 정상 작동안되거나 안끝나는 경우가 있음) 주의 요망
# 스팍의 미래
- Spark SQL이 점점 좋아지고 중요해짐
- saprk 2.0의 DataSet API
- RDD API도 점점 중요도 상승 (자유도가 높음) - 예전보다는 많이 복잡해진건 사실이지만 더 다양한 분야로 나가기 위함일듯
- tensorflow 등 프로젝트의 대용량 고성능 엔진 역할
- 기존 BI 툴들과 경쟁
- 빅데이터 분석 엔진에서 General 컴퓨팅 엔진으로 확산
# MLlib vs tensor flow
- 2.0에서 spark mllib이 나오긴 햇는데 다시 없어지지 않을까??
# [6] In-App Messaging and Chatbot
# in-app messaging

- 챗 ui + 메세징 sdk를 제공하여 내제화된 chat 기능을 구현.
# 메세지
- 기본 : text, image 등등
- 확장 메세지 : 쿠폰, 배송 조회 등 - fully customize 된 것
# conversational commerce
- 챗 인터페이스 내에서 상거래 또는 상거래를 지원하는 형태 ( 사람, 브랜드, 서비스, 봇 등)

# 최근 주목받게된 배경
— 모바일 메세징 서비스가 스마트 폰의 gateway — 텔레폰 포비아 현상의 확대 — 대화창 내에서 모든 상거래 행위 완결 가능 — 최근 상거래 트렌드 : 최근 가장 친숙한 인터페이스

- 인앱챗 형태의 커머스: skp
- 메신저 플랫폼 기반의 대화형 커머스 : 카카오톡 라인

나중에는 AI chatbot 으로 발전 가능성이 잇지
# Chatbot

- 챗 ui에서 동작하며, 자연어를 통해 context에 맞는 응답을 제공하는 커뮤니테이션 소프트 웨어 — 최근 주요 ICT 기업들의 AI 투자 및 챗봇 platform 시도 — line, Facebook, MS, google also chatbot
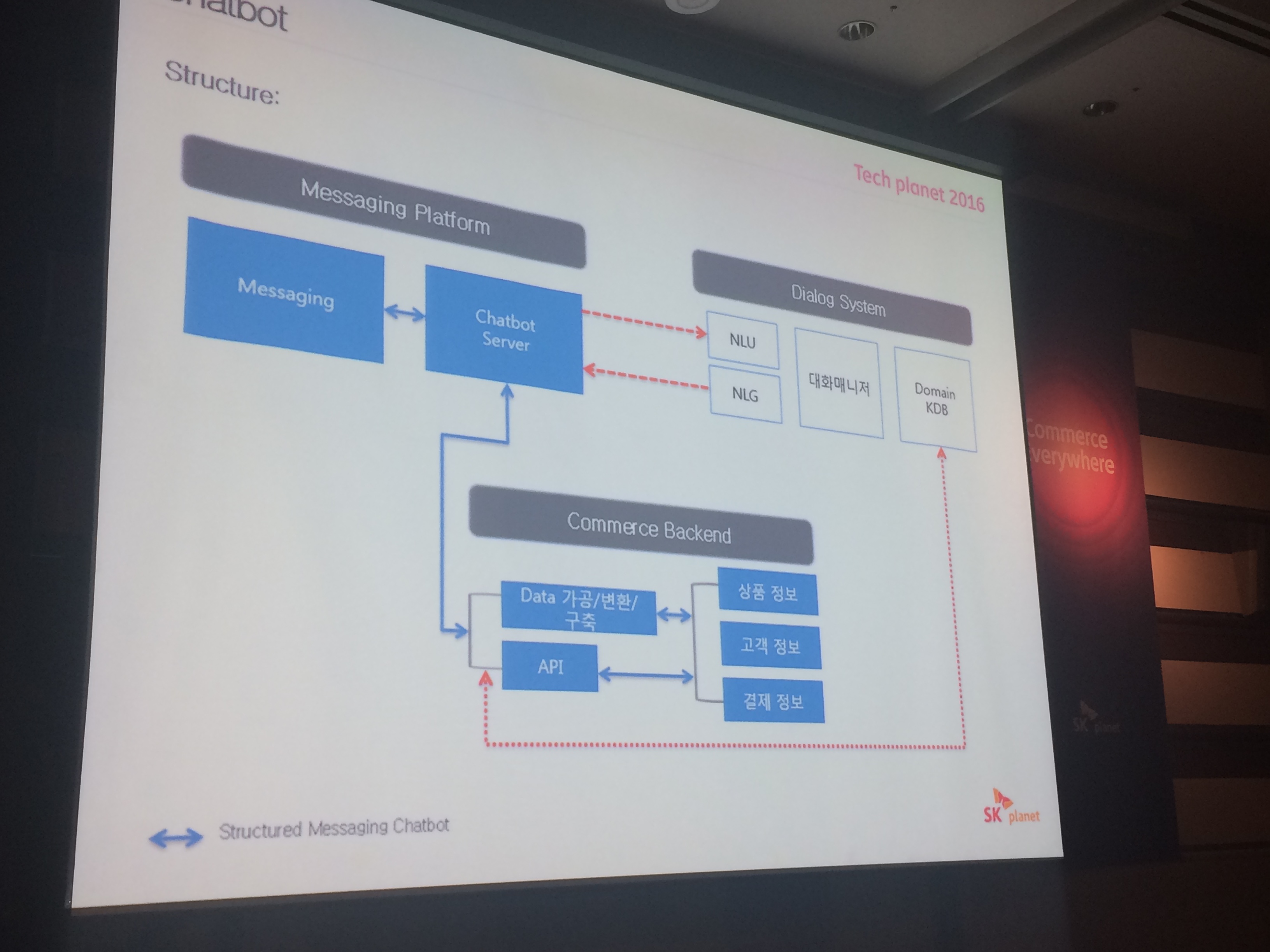
# 커머스 입장에서 필요한 것들
- 메세지 플랫폼
- 다이얼로그 시스템
- 커머스 백엔드
다 모바일향으로 잘 조합해야함. 그냥 제공한다고 되는 것이 아님.
# 구현
- skp 내 요구사항

— 셀러톡 — 지인톡 — 상담톡 — 문자쇼핑

자사 서비스, 11번가, 시럽 스타일 프로젝트 앤 등에 적용했음.
# Client side
# talk framework
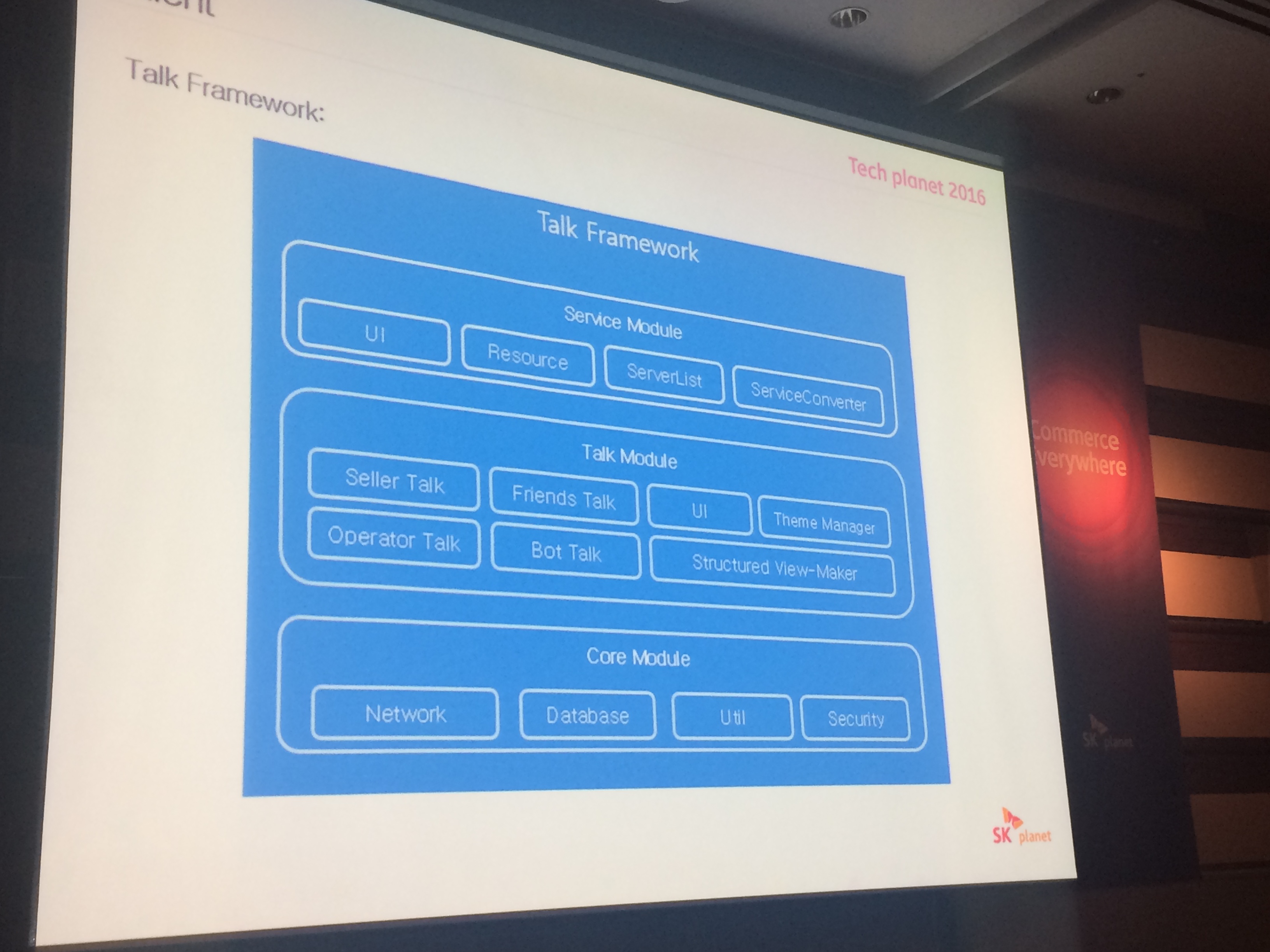
- 서비스 모듈, 톡모듈, 코어 모듈 등. 을 제공
# 고민들
- 표준화. (서비스별 서버 protocol 의 표준화 노력)
- 모듈화 - block 단위로 재사용 가능하도록
- 컨트롤 (기능별 on/off)
- 커스터마이즈 UI
# Size Reduction
- 사용하지 않는 reoucese 제거. 정적 분석을 활용해서 리소스 제거 (50%절감)
- 필요한 해상도로만 제공 : xhdpi, xxhdpi만 유지
- remove duplicate library :ex) network library dependency 중복 —> okhttp3
- reuse resources :
# structured message type
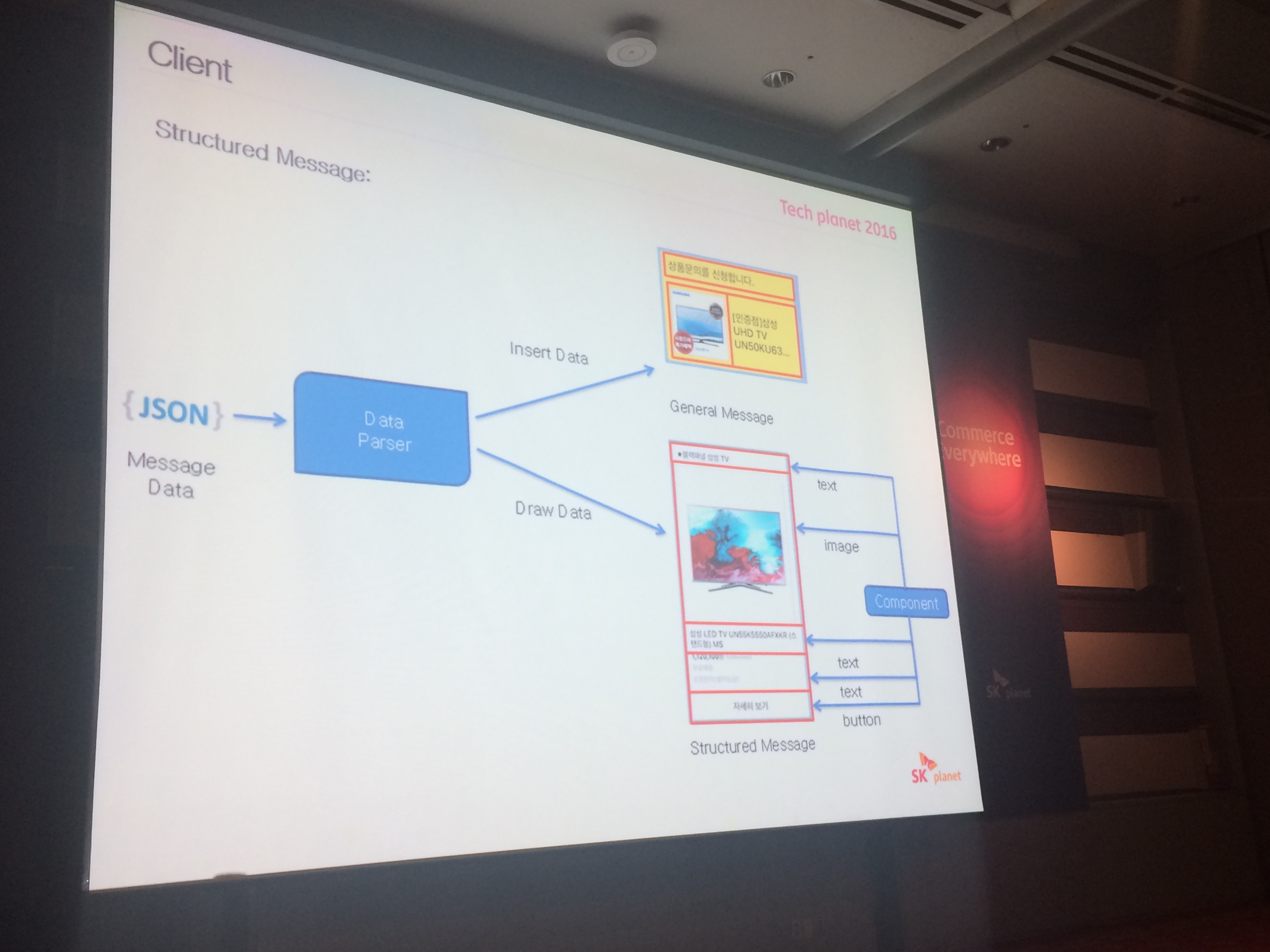



- fb 책봇 가이드 보면 msg template>> 의 슈퍼셋 정도로 이해하면 될듯
- 자유도를 많이 주고 싶엇다.
- json 으로 내려주면 UI가 나눠져서 그려진다.
- json에 action 값도 내려줘서 어떠한 버튼에 대한 액션도 다 넣어줌
# Server side
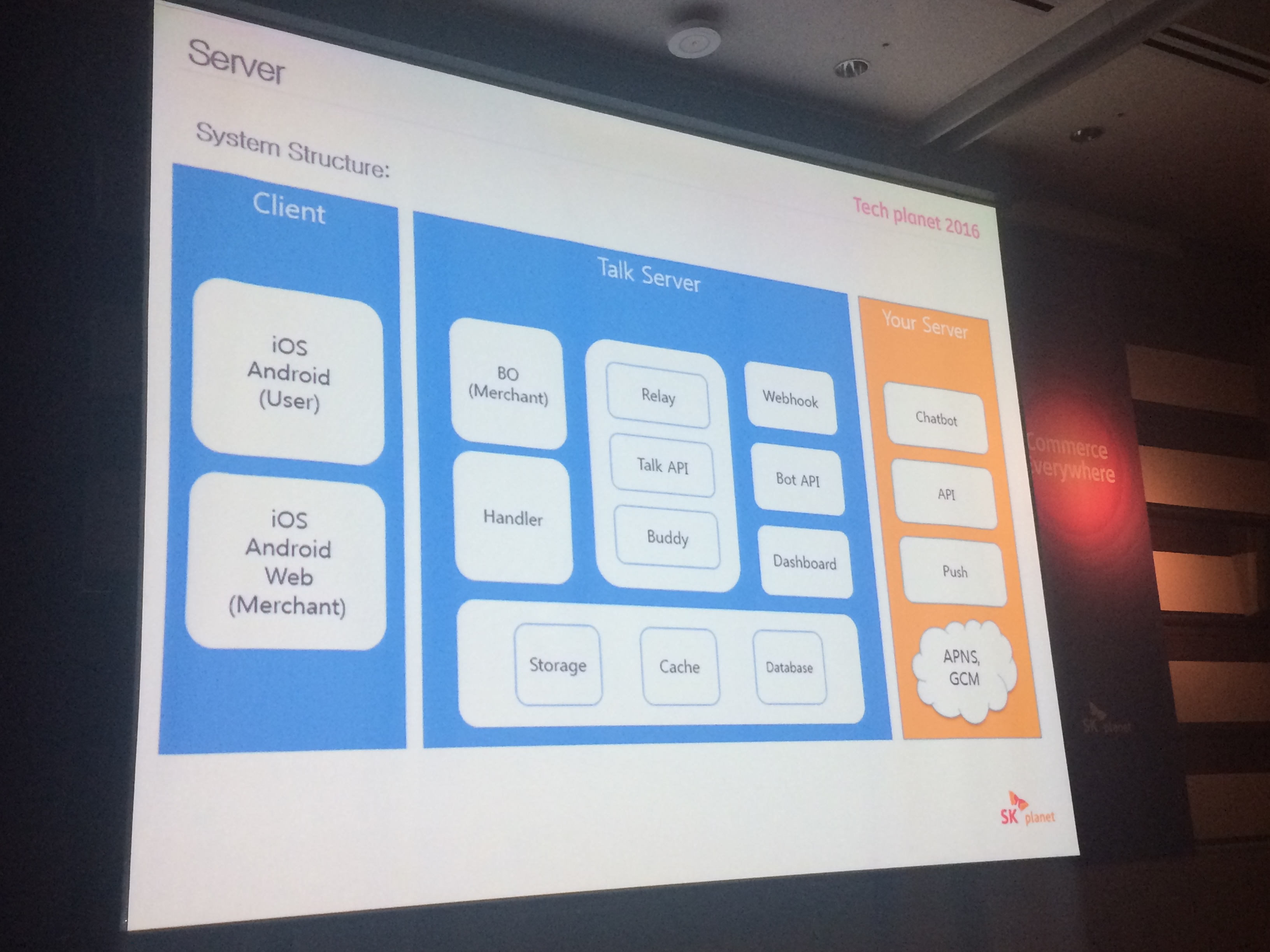
# talk server 구조
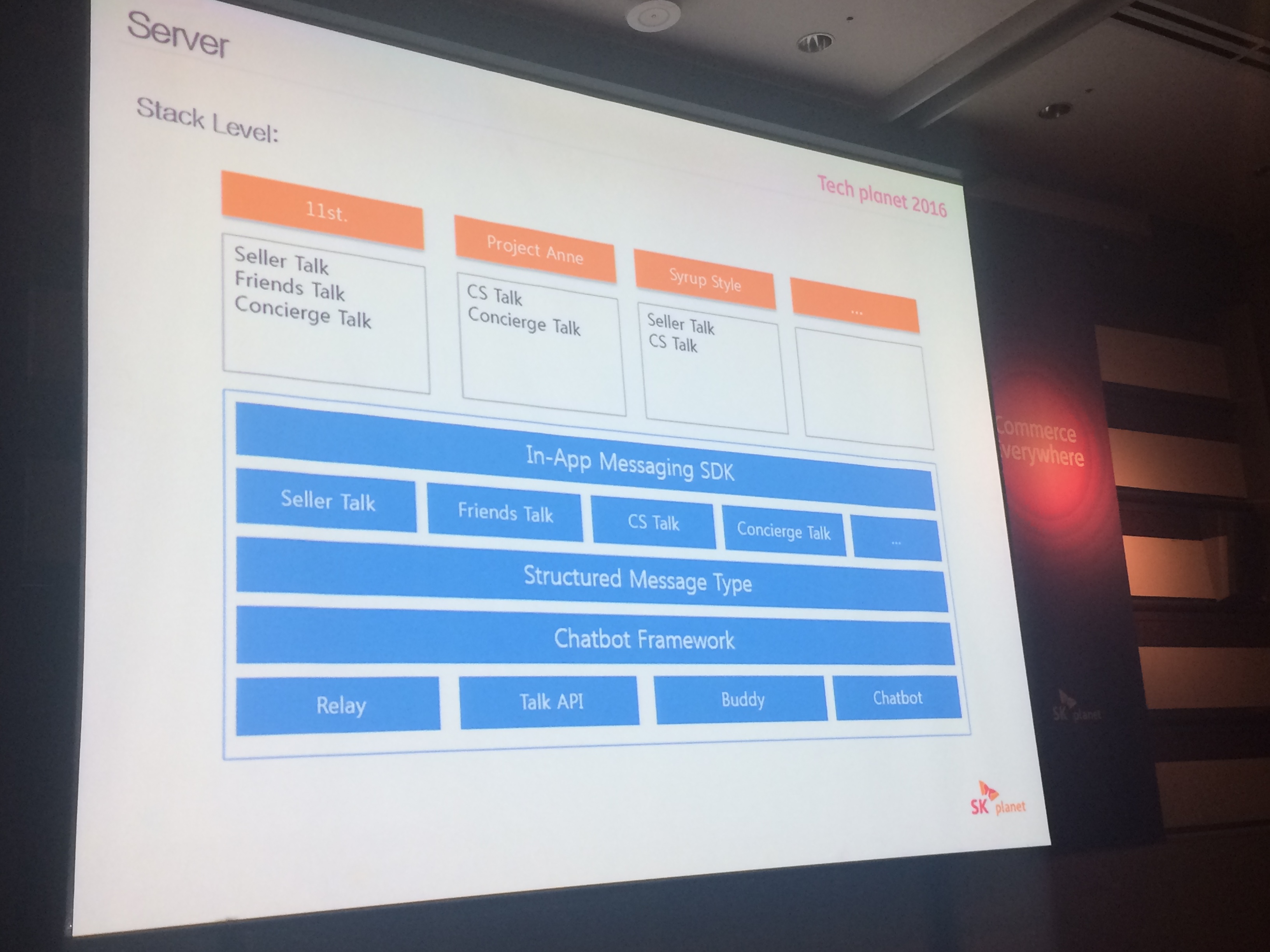
- 가장 상위에는 각 서비스들이 잇고 그 아래에는 인앱 메세지 sdk가 잇고
# stack

- nodejs
- relay server : 이벤트 드리분인데 메세지 순서 보장을 위해 서버시간을 부가 정보로 전달 하여 판단
- network 이슈 처리 대한 처리
- IE 지원 후덜덜
# 웹훅
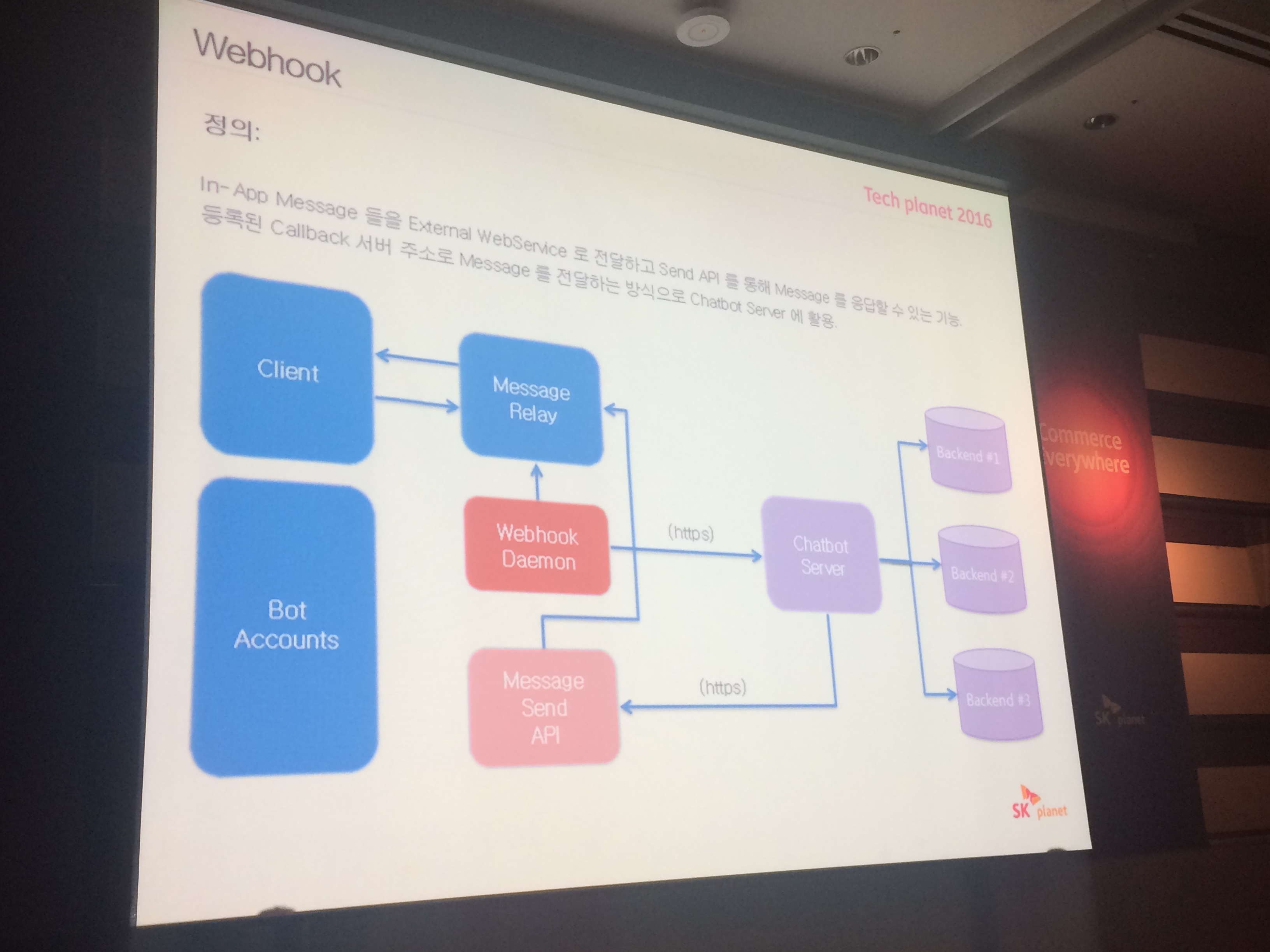
structured msg, 웹훅, send api
암호화, 데이터 변조 방지, 메세지
# [7] Google Tensor Flow & Machine Learning in the Cloud
- 발표자 : 클라우드 플랫폼 팀에잇는 advocate
# 뉴럴 네트워크 & 딥러닝
- 뉴럴 네트워크 : function that can learn
- 어떤 어플리케이션이든 적용할 수 있다. ex) 게임 서버,..
- 텐서플로 플레이 그라운드 써볼수 있다.
# 머신러닝이 구글 어디서 쓰이는지
- 구글 검색 : rankbrain이라는 딥 뉴럴 네트워킹을 사용하는데 이게 서치 랭킹 매기는데 사용댐.
# ex
Google Photos
Google gmail : 답장 10%가 모바일에서 누른걸로 답변이 되고 잇음. (선택지가 밑에 나오네)
Google translation
Google 뉴럴 사용하고 나서 data center cooling energy 40% 아낌.
딥 러닝을 점점 더 쓰고 잇음.
# 머신러닝의 확장
- 구글에서 제공하는 machine learning
- 기존 ml api는 사용하기 쉽고
- 텐서플로, 클라우드 머신의 경우 커스터마이즈를 더 할 수 있음
# Could Vision API
- http://vision-explorer.reactive.ai/ (opens new window)
- https://cloud.google.com/vision/docs/samples (opens new window)
- cat이라는걸 봣을때 pet이라는것까지 꺼냄. 아마 배경이 집이라서? (wow)
- 사람/ 사람마다 detect 기분, 틸트 등 분석. Wow
- 랜드마크 detection 사진속에 장소가 어디인지 map에 표시
# Cloud Speech API
- pre-trained models
- ml 스킬은 요구되지 않음.
- 오디오를 들으면 txt로 변환
- natural language api. 문장을 쓰면 그 안에 entity, sentiment, syntax들을 뽑아냄.
# 텐서플로
위의 api로는 모든 것들을 다 포괄 하기가 어려움.
오픈소스, 머신 인텔리전스
2015년 11월에 런치
많은 ML 프로젝트에 쓰이고 잇음
가장 popular한 ml 프로젝트
시작하기가 쉬움.
예전에는 이해 안되는 부분도 알앗어야 햇는데 텐서플로 같은 경우에는 내용물을 다 알필요 없고 interface구현만 잘 하면 된다.
# portable and scalable
- 맥, 윈도우에서 다 돌고
- GPU
- prediction on :
- Android and iOS
- rasPi and TPU
# TensorFlow in the Wold (democratization of deep learning)
텐서플로가 어디쓰이는지
ex) 오이 농사
텐서플로를 통해서 모양별로 cucumber sorting 하도록.
참고 : tensorflow cnn cucumber (opens new window) 후라이드 치킨도 분류해준다 ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
soring garbages등 recyle인지 compost 인지
드론에 적용해서 트럭 갯수 새기
# Challenges
- dnn은 은 트레이닝할 dataset이 필요하고 시간도 많이 필요함
- 고로 google cloud가 필요하다.
- Google Cloud 는 the datacenter

구글 자체 jupiter 네트워크를 가지고 있음.
distributed Training with Tensorflow
# Tensor Processing Unit

- CPU GPU도 아닌 TPU라는걸 만들고 잇음.
- Cloud를 쓰면
- 스펙이 빠방함.
- 엄청 오래걸릴꺼 금방 끝냄.
# Cloud Machine learning (Cloud ML)
- 커스텀 텐서플로 그래프.
- 클라우드 데이터 플러우와 integrated
# use cases
ex) AUCNET - 일본기업
- 내 차 여러개의 사진들을 올리면 각 차의 파트를 detect 하고 (using tensor flow)
- 이게 앞면인지 뒷면인지 등등
- 그리고 어떤 차인지 , 가격대는 어떻게 되는지 내줌.
# [8] 빅데이터와 자연어처리 기술을 이용한 11번가 상품 추천
- 사용자의 소비 패턴, 을 모델링을 하고 그 결과에 따라 사용자가 관심을 가진 부분을 알아내서 추천하는것
- 사용자가 소비 성향을 보여주는 것 . 이력상에 잇는 상품들을 분석하고, 소비자를 모델링 >>> 추천
# 추천 시스템 배경과 목적
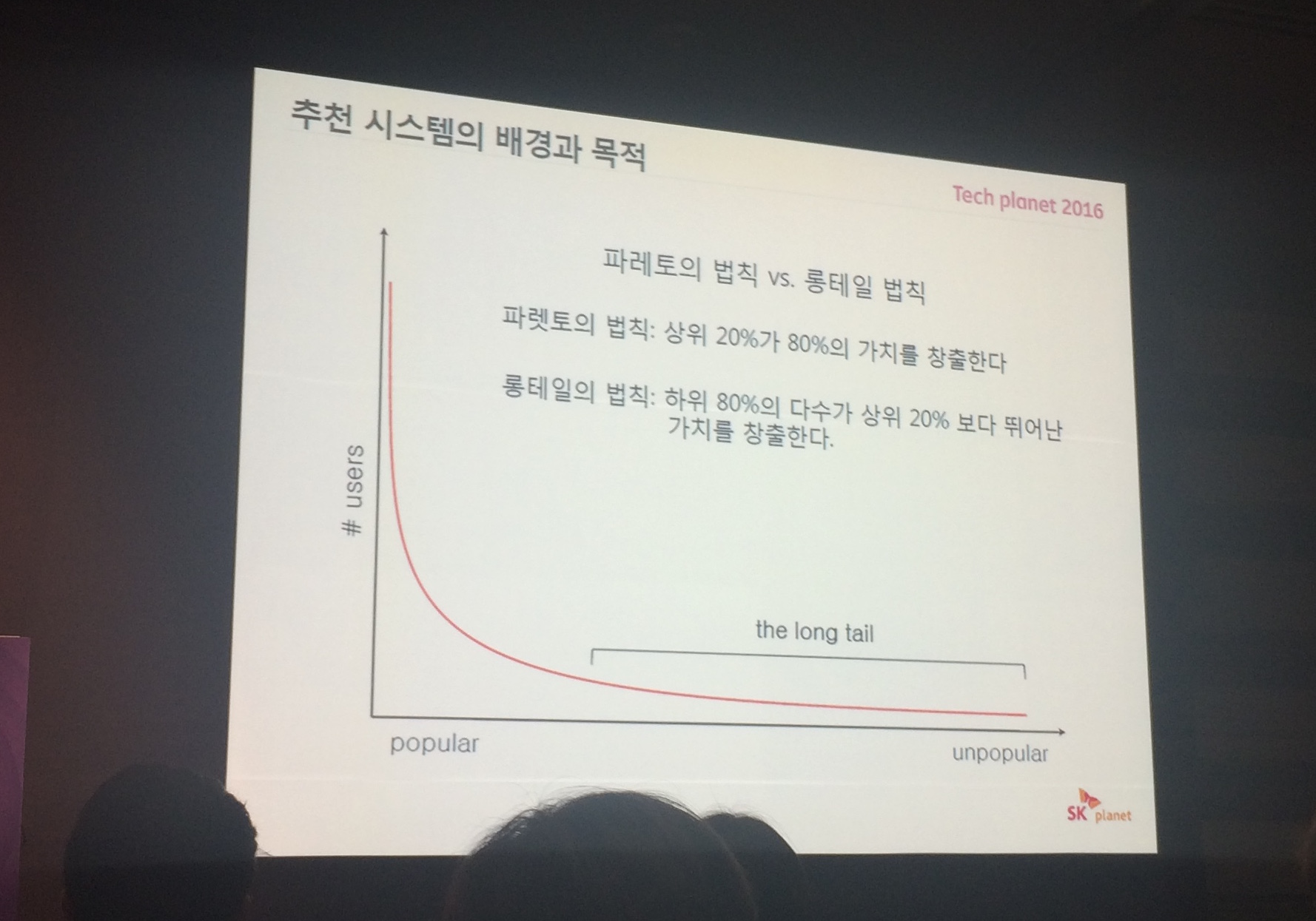
상품수는 많지만 20%가 거의
80%를 버리는게 아니라 20% 못지않은 큰 가치를 창출해 내야한다 > 새로운 서비스. 새로운 수익모델을 만들어 내는것 . : 롱테일
개인의 다양성을 중시해 롱테일을 실형
netflix , amazon
요즘은 정보홍수, 기호에 맞게 취사 선택 환경 제공이 중요해짐.
방대한 데이터 속에서 사용자에게 맞게
사용자 행동 이력, 관계, 상품 유사도 등으로 관심 상품을 자동으로 예층하고 제공하는 시스템 : 추천 시스템 정의.
# 추천 알고리즘 고찰
# 협업 필터링 ( CF : collaborative filtering )
- kNN-based : 나의 이력을 기록했다가 추천 , 사용자 간의 유사도 : 나랑 비슷한 사람이 소비한걸 추천 user-based, item- based
- Model-based:
- ex) 아마존
- item similiarity DB를 구축하여
- 사용자가 사고 > 평점 남기고 > user-pforile에 기록, 유사 상품 DB를 미리 만들어놓고 랭킹하여 추천
- 사용자의 구매, 방문 클릭 을 기반으로
# 기존 CF의 장단점

장점: 최소한의 기본 정보만으로도 구현 가능
다양하게 적용 가능
단점 : 고차원, 저밀도.
새로운 사용자나 아이템이 추가되는 따르는 확장성이 떨어짐.
# 더 완화한 모델
- Model-based CF 알고리즘 — 데이터 내에 잠제되어있는 속성을 leanring하여
- 패턴 속성을 알아내서
- 공통된 속성을 뽑아내서
# content-based filtering
- 아이템의 속성을 기반으로 유사 속성 아이템을 추천.
- 아이템 자체를 분석하여 추천 (반면,CF는 사용자의 행동이력 )
- 아이템 분석 및 유사도를 측정하는 것이 핵심 — 자연어 처리등을 사용
# 추천 알고리즘의 장단점

- CF vs CBF
두가지를 융합하여 + 딥러닝 추천알고리즘을 만듬
-상품과 사용자에 대해 연관성을 확인해 distributional semanric model
# distributional semanric model

언어에서 많이 쓰이는것
단어에 의미는 그것이 사용되는 용례에 대해 그 의미가 추론 될 수 있다.
DSM은. 단어가 각각 다른곳에서 쓰일때 통계를 내서 단어의 의미를 추론하는것
사용되는 기술 — word embedding 단어의 의미와 맥락을 고려해 단어를 벡터로 표형한것 >> Word2Vec 알고리즘. 을 이용 : 같이 자주 출연할수록 단어의 뜻이 유사하다. 추론 가능
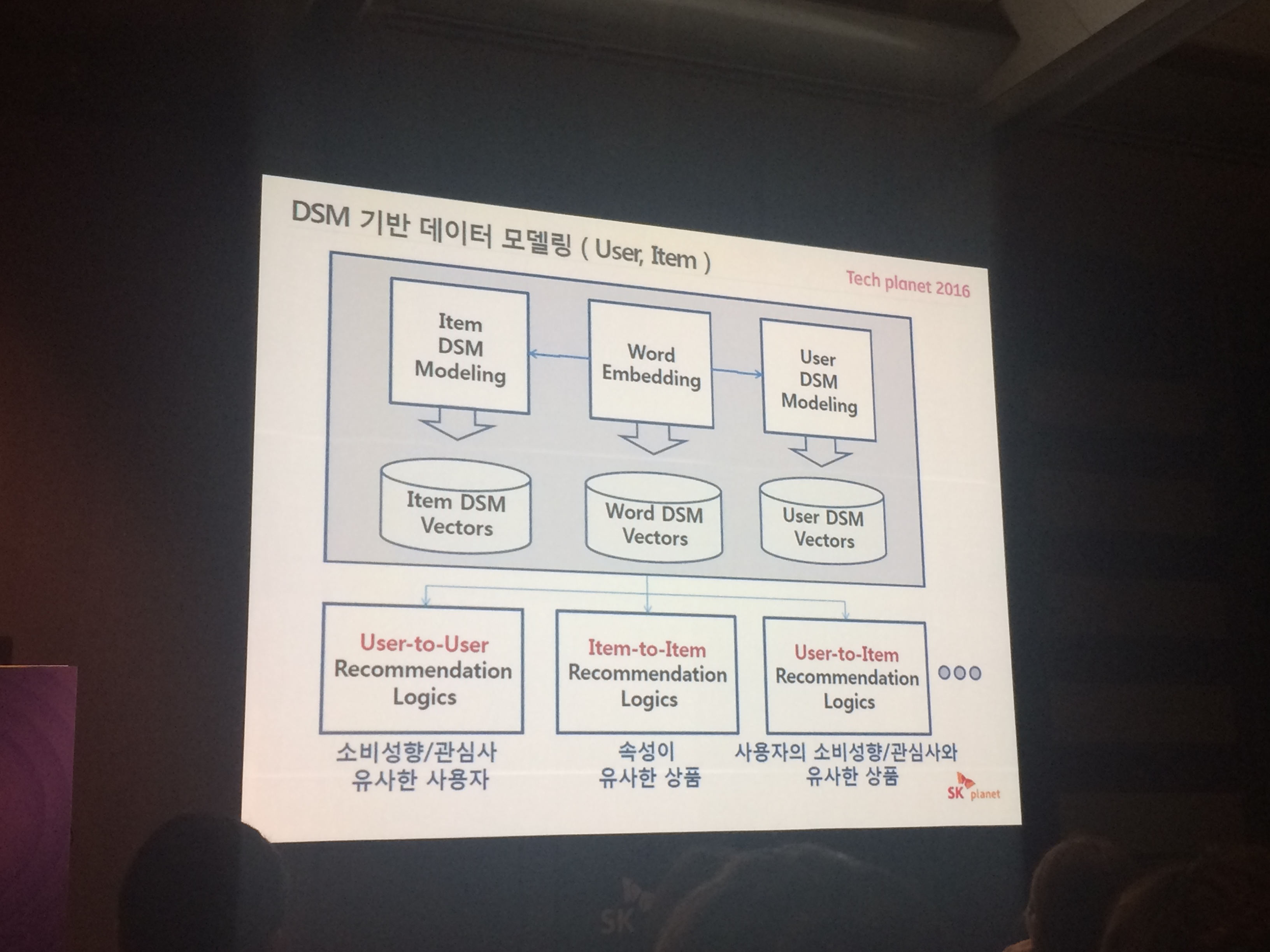
# 그럼 추천에는 어케 사용되엇는가

- 사용자와 상품을 모델링 -> 이 둘 사이 메트릭스에서 유사도를 찾아냄.
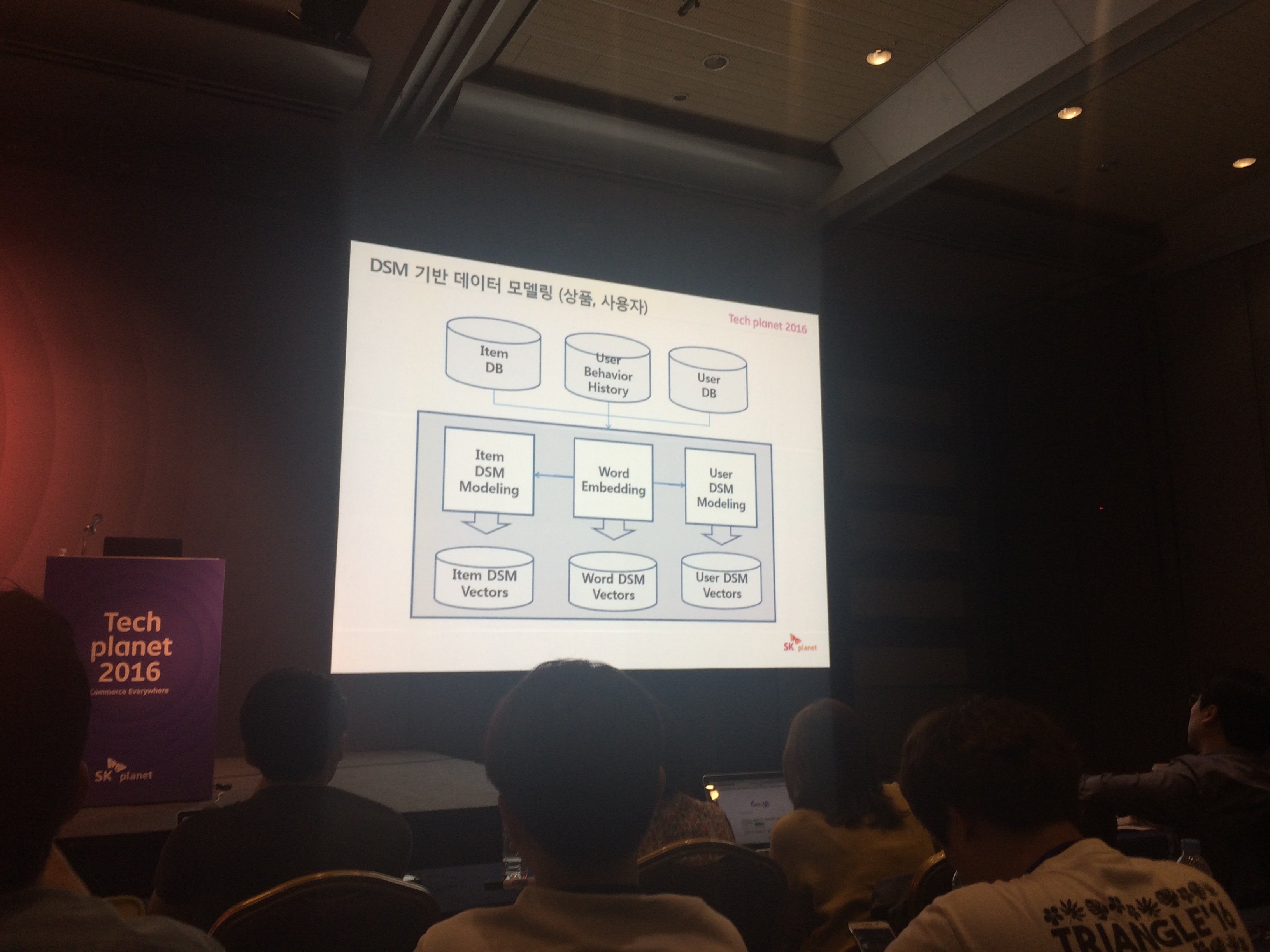

- law data : 상품 디비와, 행동이력 디비, 사용자 디비 를 쌓아서
- 이걸 기반으로 word embedding을 이용하여 Item과 User DSM modeling
# 모델링은 어떻게 하는가
사용자 소비 관련 행동 분석과 그에 관련된 상품 정보 속성을 모델링 — 검색/클릭/구매/리뷰 같은 행동을 분석 -(사진) 키워드 검색, 감성 분석 등.
과거 상품에 대한 분석
# 시스템 구성


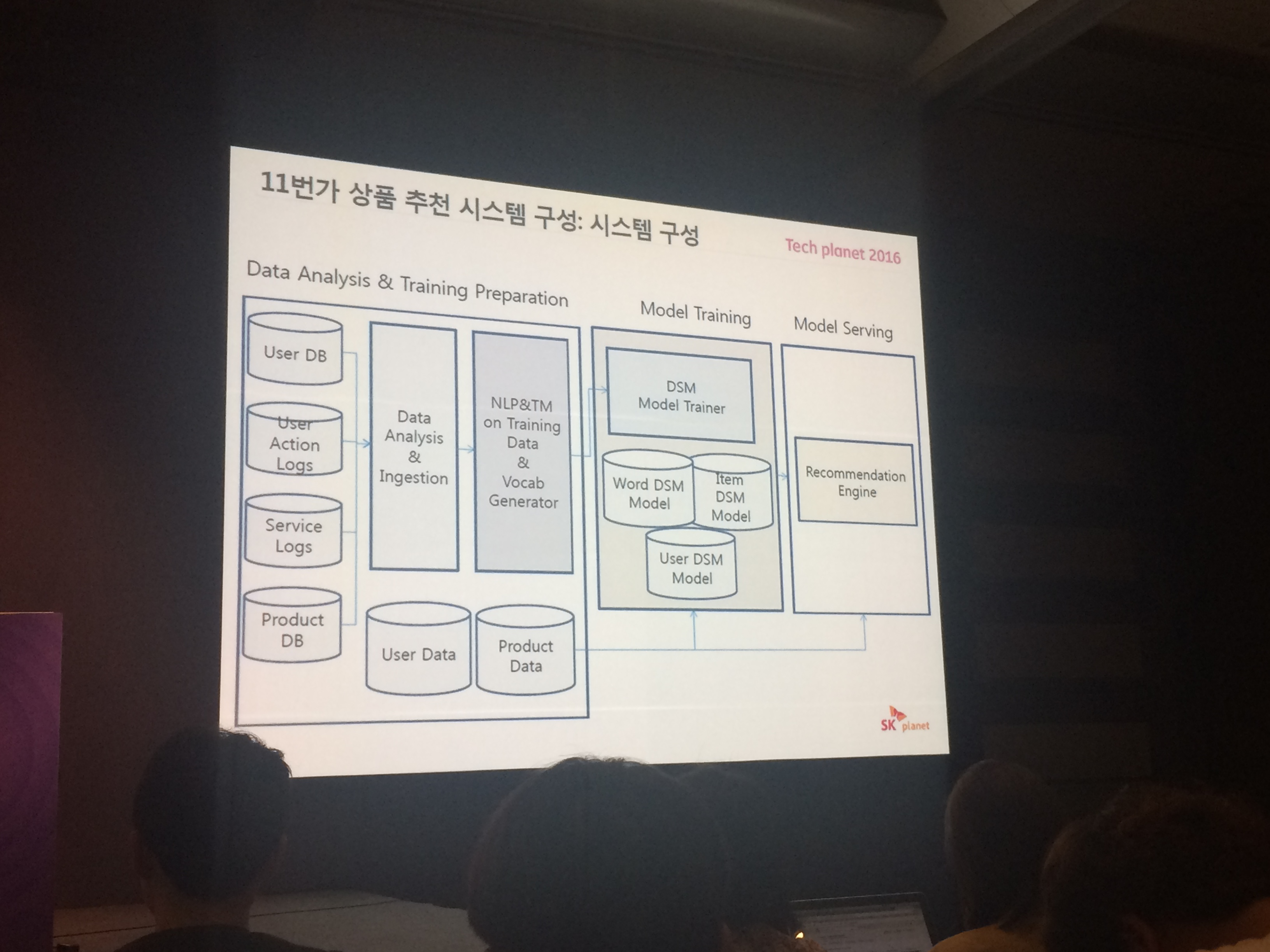
- Data Analysis & training preparation
- Model training
- model serving

# [9] Facebook Chatbot M messenger
# cybelle
# 튜링
- 튜링 테스트 20s 후 이게 휴민인지 컴퓨터인지
# eliza
- 1966년
# AI come back
- machine learning eventually work: make fomular and input to output
- 예전과 다르게 머신 러닝이 잘 동작함
- Messaging platform are exploding —> offline > website >> mobile app >> messaing — 이제 메세징이 인터넷을 쓰는데 보편적인 방법이 되엇음.
# Bot
- conversation : in direction
- natural language is optional
- 채널이 많아짐 messager, sms, web, voice , siri 등등
# use cases
# Spring
- shopspring.com : e-commerce 플랫폼
# KLM
- airline company
- question을 넣으면 굉장히 자세한 답이 오네.. 신ㄱㅣ
# 봇 vs 앱
# 봇 장점
— 따로 깔 필요요가 없고
- 공짜 . (메세지 플랫폼에 따라 다르긴 하지)
- 노티피케이션, authentication , 페이먼트 등등
- 문맥이 항상 이어짐 the thread always cantina contest
- collabration ( 대화 윗 여러 사람과 봇) : 대화창 내에서 여러사람과 함께 사용할수 잇음.
# 만들기
- write “job spec” 스펙 짜기
- start with a simple implementation
- 질문이 들어오면 자연어 처리를 통해서 intent 와 recipe을 나눠서 Dialog manager에 넣어줘서 답을 찾고 자연어 처리를 통해 인간 언어로 바꿔주고
- simplify the world
- development workflow
- wit.ai (opens new window)
- natural
- Set expectation
- Ship early and ofter